Exploring STC: Self-training approach for short text clustering explained
STC stands for Short Text Clustering. There are a few steps involved and the original paper (by Amir Hadifar, Lucas Sterckx, Thomas Demeester and Chris Develder) uses some complex words so it might seem daunting, but once you understand it the concept is quite simple and intuitive. So, what is STC?
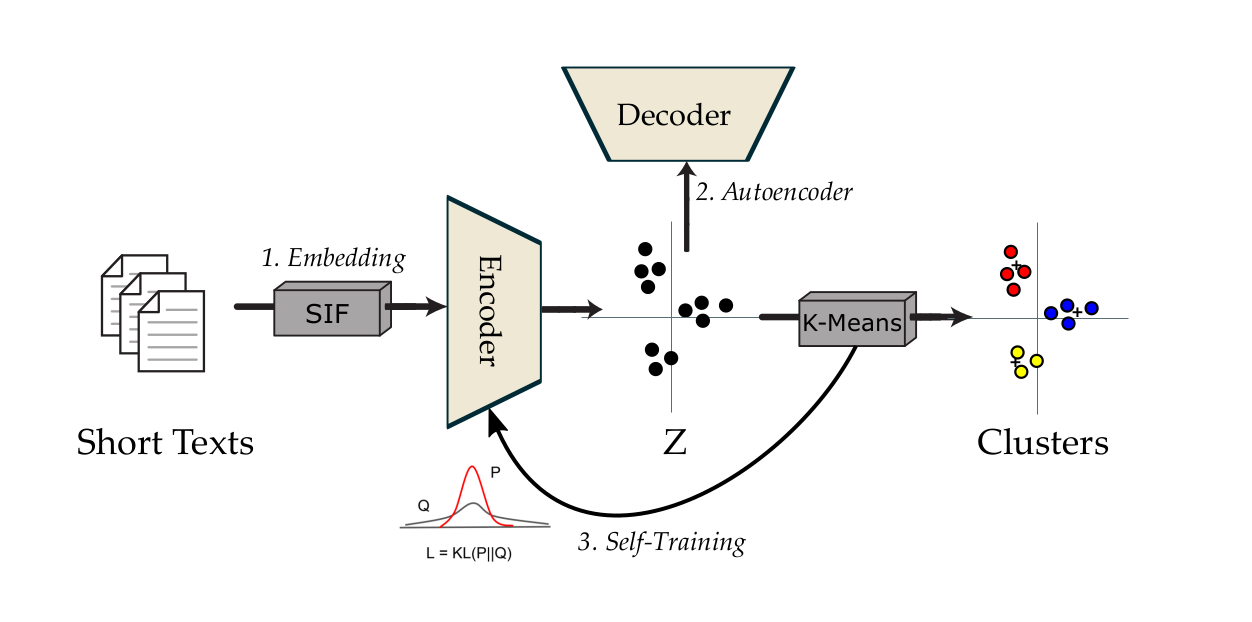
Short text clustering (STC) is the process of grouping short text documents into clusters based on their semantic content. STC is often used in various fields, including email classification and social media comment classification. Unlike longer text documents, short texts often present unique challenges in terms of processing and representation due to their limited size and sparse vector representations when using methods such as Unlike longer text documents, short texts often present unique challenges in terms of processing and representation due to their limited size and sparse vector representations when using traditional methods such as bag-of-words or TF-IDF.
The approach proposed in this article consists of several steps:
SIF embedding In order to improve data representation, the approach proposes the use of an additional transformation on the embeddings, the Smooth Inverse Frequency (SIF) method (Arora et al., 2017), in order to simplify and make clustering more efficient.
The SIF method is a method of vector representation of words that aims to capture the semantic meaning in a text corpus and to weight word embeddings by their inverse frequency in order to reduce the importance of the most frequent words, which have less semantic information, and to focus more on rare words. The contribution of each word is calculated as follows:
where is a hyperparameter and is the empirical frequency of words . SIF is widely used in text processing tasks such as text classification, text clustering, and information retrieval.
Self-training Steps
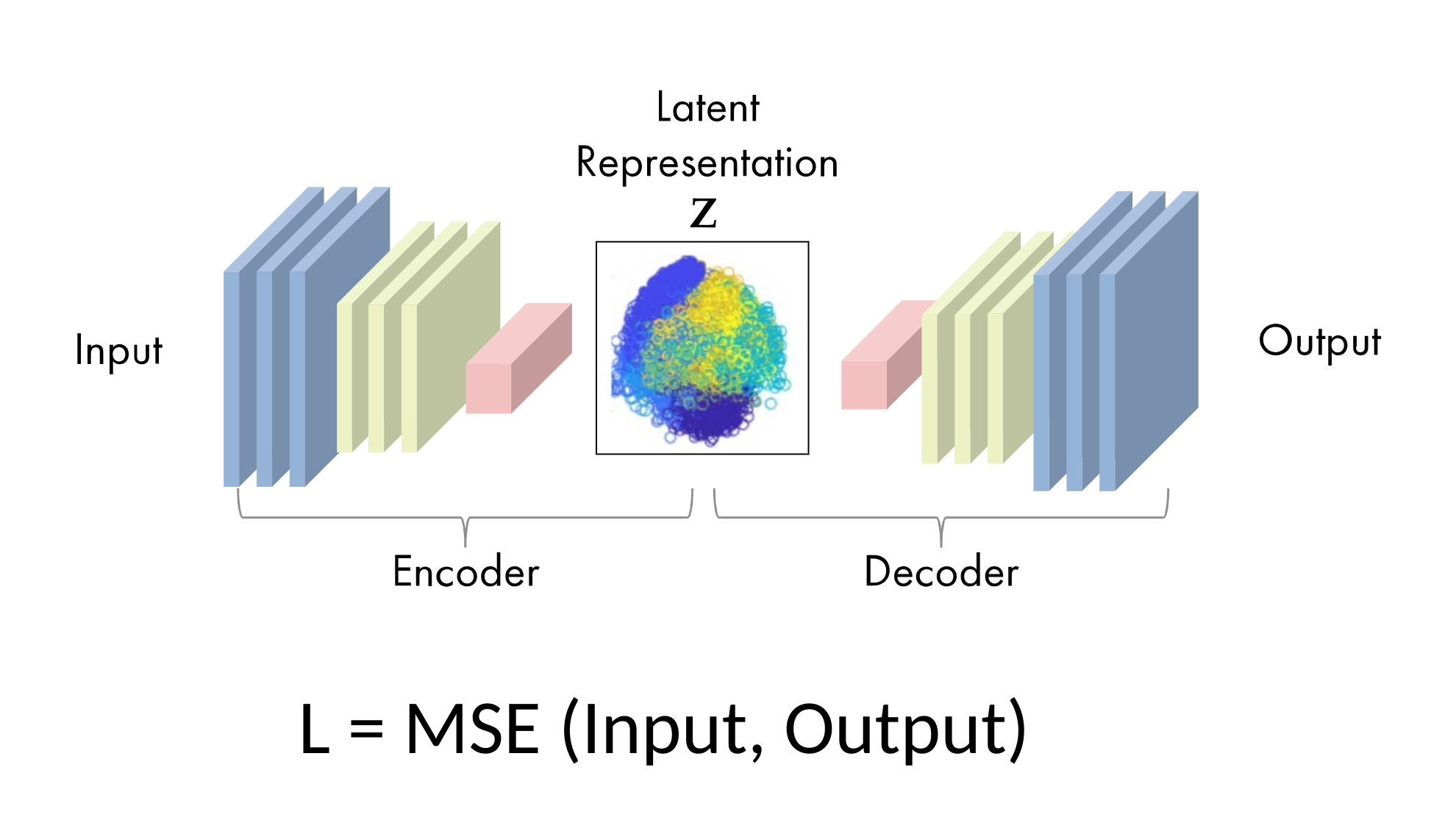
1 - Train autoencoder
The aim of an auto-encoder is to have an output as close as possible to the input. In our study, the mean square error is used to measure the reconstruction loss after data compression and decompression. The autoencoder architecture can be seen in the figure below.
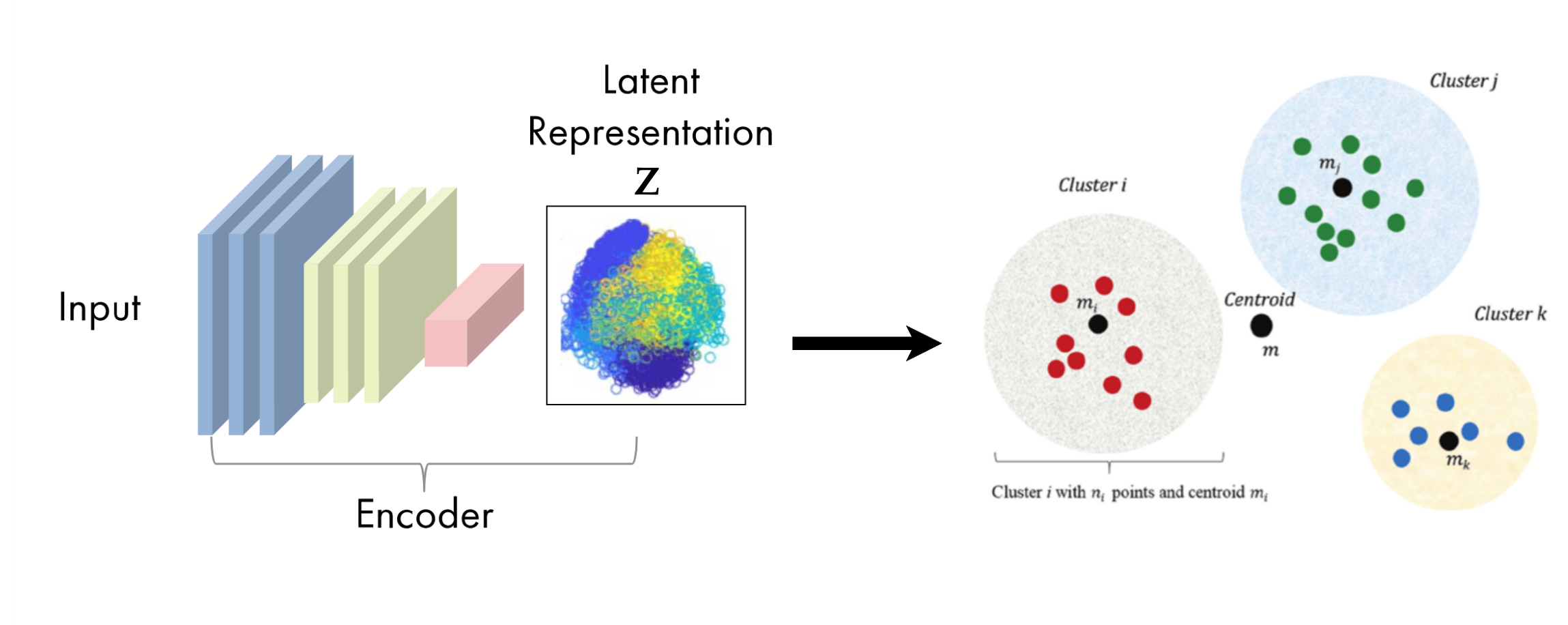
2 - Initialize centroids
It consists of initializing the centers or centroids of the clusters using a KMeans-like algorithm applied to the representations of the latent space, which we denote here as .
3 - Self-training
This is an unsupervised algorithm that alternates between two steps. First, a soft assignment is calculated between the latent representations and the centroids, denoted here as Q. Next, a joint update of the centroids and encoder weights is performed based on the current confidence assignments using an auxiliary target distribution, denoted here as P. This process is repeated until a convergence criterion is met.
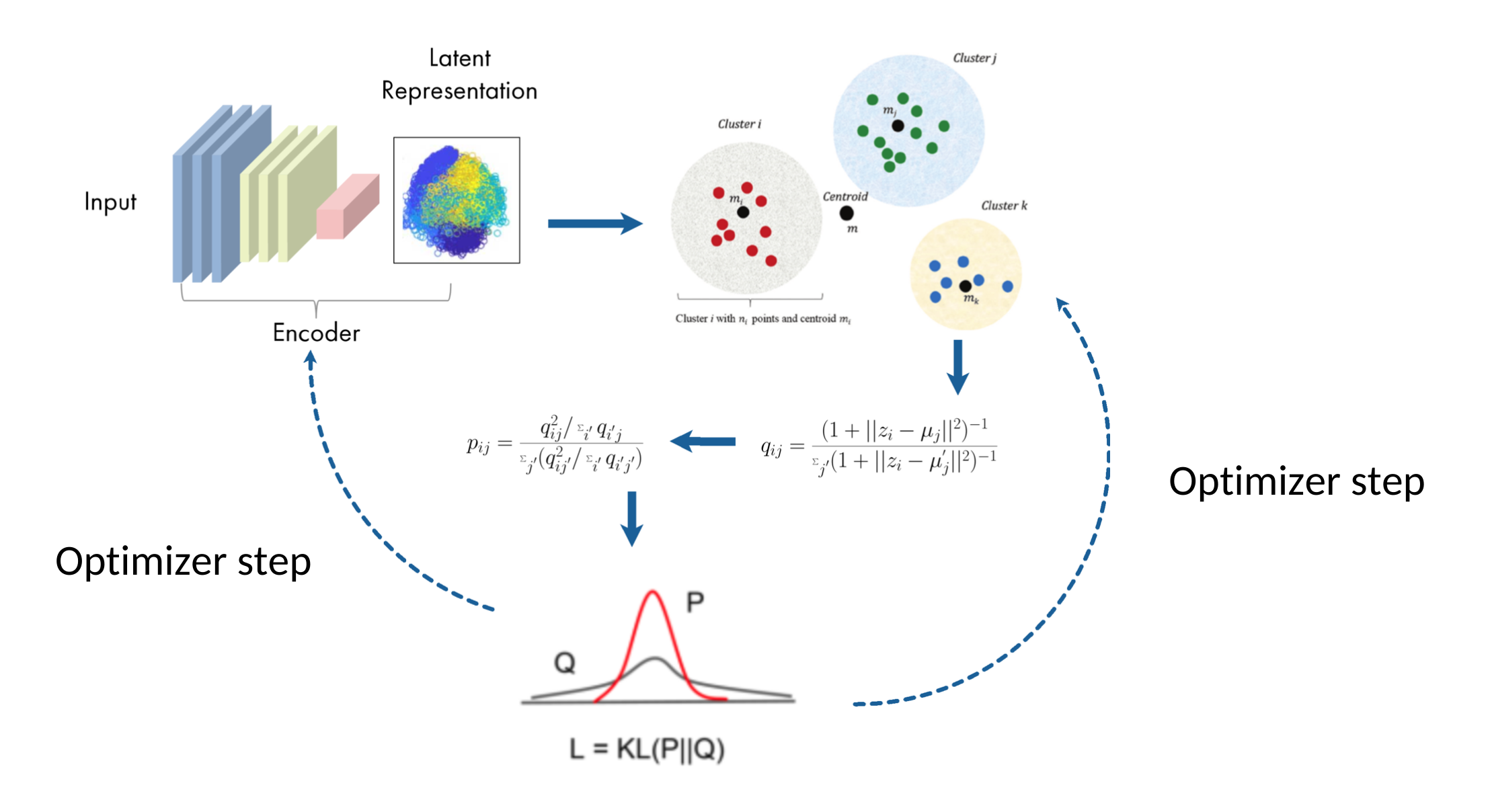
Soft-assignment
Similar to van der Maaten & Hinton (2008), the method uses the Student's t-distribution as a kernel to measure the similarity between the representation 𝑧𝑖 of latent space and the centroid 𝜇 𝑗:
𝑞𝑖 𝑗 can be interpreted as the probability that an individual 𝑖 is associated with a cluster 𝑗.
KL-Divergence Minimization
The objective function used in self-training is defined as follows:
This function allows you to compare two distributions. The STC model is trained to match the distribution Q (soft assignment) to that of the target distribution P, thereby optimizing data representation (updating encoder weights) and clustering (updating centroids) In order for the target distribution to have the following properties: (1) strengthen predictions (i.e., improve cluster purity), (2) place greater emphasis on data points assigned with high confidence, and (3) normalize the contribution to the loss of each centroid to prevent large clusters from distorting the hidden feature space, the authors proposed the following calculation:
Evaluation Metrics
The evaluation of the clustering performance is done using the following metrics:
Clustering Accuracy (ACC): Measures the percentage of correctly clustered samples.
where is the true label of sample , is the cluster assignment of sample , and is a mapping function that maps each cluster to a true label.
Normalized Mutual Information (NMI): Measures the mutual dependence between the true labels and the predicted clusters, normalized to account for chance.
where is the mutual information between the true labels and the predicted clusters , and and are the entropies of the true labels and predicted clusters, respectively.
Adjusted Rand Index (ARI): Measures the similarity between the true labels and the predicted clusters, adjusted for chance.
where is the Rand Index, which counts the number of pairs of samples that are assigned to the same cluster in both the true labels and predicted clusters, and is the expected Rand Index under random cluster assignments.
The STC approach has been evaluated on several datasets, including the SearchSnippets dataset, which consists of short text snippets extracted from search engine results. The results show that the STC approach outperforms traditional clustering methods and other state-of-the-art approaches for short text clustering.
Conclusion
The STC approach is a powerful method for clustering short texts, which are often difficult to cluster due to their limited size and sparse vector representations. By using an autoencoder to learn a latent representation of the data and a self-training algorithm to optimize the clustering, the STC approach can achieve high performance on short text clustering tasks. The use of SIF embeddings further improves the data representation and clustering performance. Overall, the STC approach is a promising method for short text clustering and has potential applications in various fields, including email classification and social media comment classification.